Neogramme, eine Untersuchung
Im Frühjahr habe ich begonnen von einem wissenschaftlichen Standpunkt aus mich mit den Worterfindungen aus phrasardeurs verbarium zu befassen. Ausschlaggebend war eine Automobilbeilage einer Zeitung, wo es diese netten Diagramme hatte. Die Diagramme waren nicht besonders aussagekräftig, sie gaben dem Artikel aber einen technischen, ja sogar wissenschaftlichen Touch.
In diesen Diagrammen visualisiere ich nun einige Sachverhalte der Worterfindungen. Als Ausgangspunkt dient jeweils eine Worterfindung und das “Original” dazu bzw. das Ausgangswort wovon die Wortschöpfung abgeleitet ist.

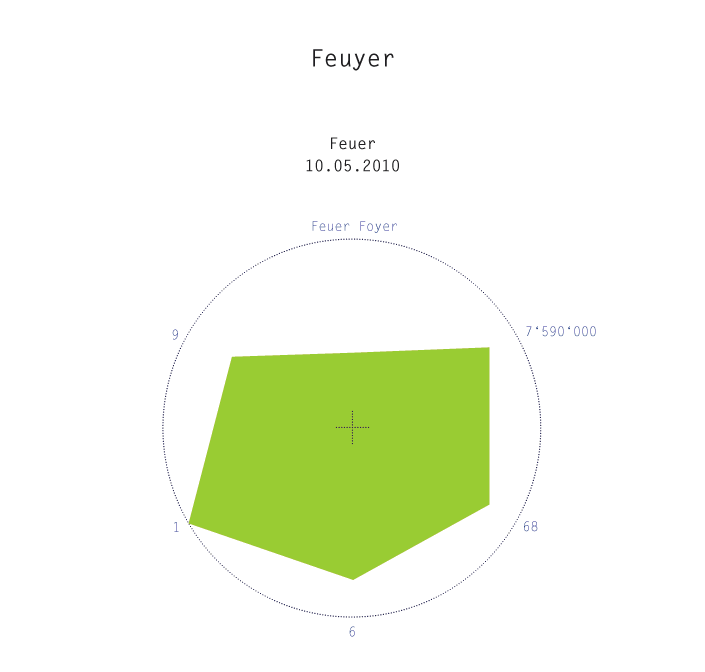
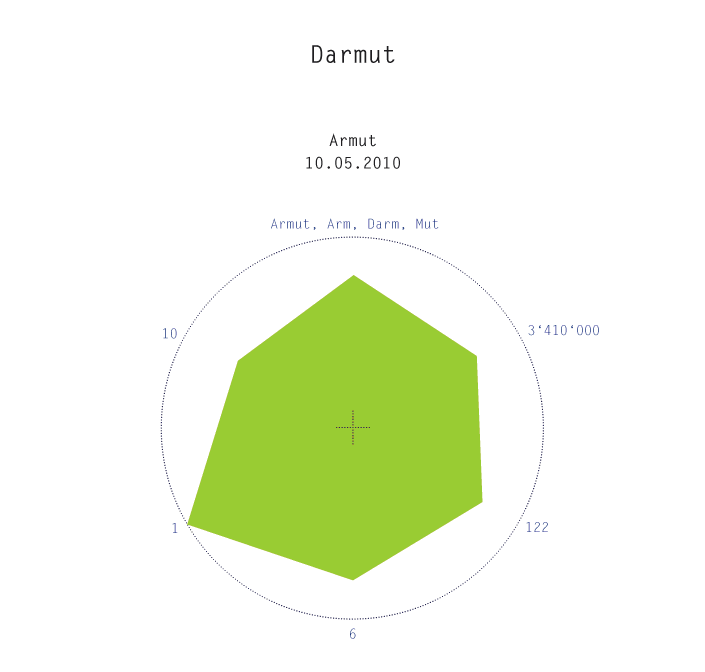
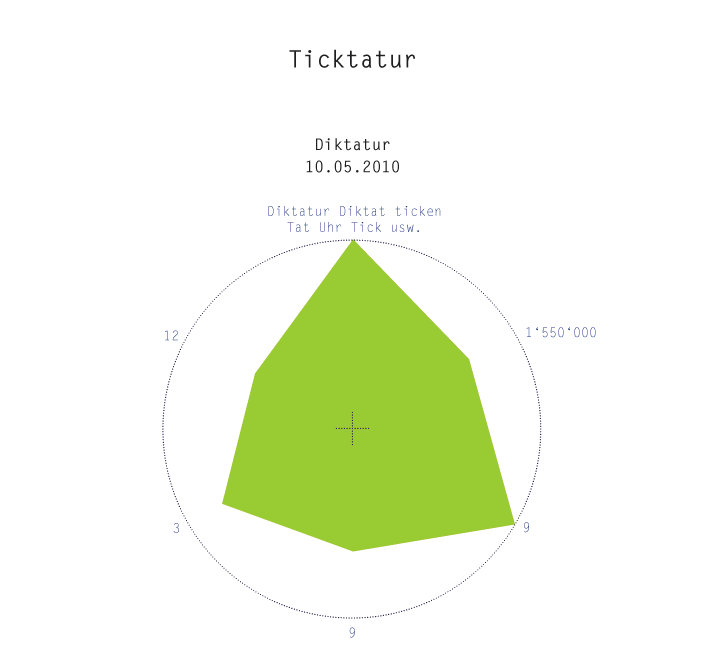
Die 6 Parameter der Darstellung sind:
- Bezüge der Worterfindung zu existierenden Worten oder umgekehrt: was für Begriffe im Wort mitanklingen. Je mehr desto besser, weshalb die Skala von innen gegen aussen angelegt ist. Jedes Wort verfügt über mindestens einen Bezug, nämlich denjenigen zum “Original”.
- Anzahl Treffer für das Ausgangswort. Gesucht mit einer erweiterten Suche bei Google mit dem Ausgangswort als Phrase und innerhalb der Sprache Deutsch (wo nicht anders angegeben). Die Werte ansteigend von innen gegen aussen, da eine Grosse Trefferzahl für eine weite Verbreitung bzw. eine gewisse “Geläufigkeit” des Ausdruckes spricht. Der Stichtag der Suche ist unter dem Ausgangswort in der Darstellung aufgeführt.
- Treffer für die Worterfindung. Gesucht mit einer erweiterten Suche bei Google mit der Worterfindung als Phrase und innerhalb der Sprache Deutsch. Die Werte ansteigend von aussen gegen innen, ein geringes Vorkommen spricht ihr für die Einzigartigkeit des Wortes. (Einge Wörter kommen z. Z. sogar nur in enzyglobe, phrasardeurs verbarium, vor)
- Die Anzahl der Buchstaben des untersuchten Ausdruckes. Wörter mit vielen Buchstaben eher innen, Wörter mit wenigen Buchstaben aussen.
- Abweichungen vom Original. Eine nur ansatzweise aussagekräftige Grösse, da ich nur von der Schreibweise des Wortes, nicht aber von der Aussprache ausging.
- Die Häufigkeit des Ausgangswortes gemessen an der Häufigkeit des Wortes “der”. Diktatur z. B. ist rund 12 mal häufiger als das Wort der. Ermittelt beim Wortschatzportal der Uni Leipzig.
Die Werte habe ich insgesamt so angelegt, dass eine möglichst grosse Fläche ideal ist. Ich möchte also Worte zu finden, welche
- Möglichts viele Bezüge zulassen, ergo vieldeutig sind.
- Deren Ausgangsmaterial häufig vorkommt, also als bekannt vorausgesetzt werden kann.
- Die noch niemand “erfunden” hat oder zumindest noch nicht viele. (Tippfehler oder Schreibfehler, also unbeabsichtigte “Wortschöpfungen, sind in den Google-Treffern mitenthalten. Je mehr Abweichungen zwischen Original und abgeleiteter Worterfindung aber bestehen, umso geringer ist die Chance für solche “falsche” Treffer)
- Die Wörter sollen möglichst kurz sein. Bekanntlich kann man im Deutschen durch Aneinanderfügen von Worten ganz einfach Neuwörter kreieren, wie z. B. “Eisenbahnwagenachsenaufhängung”. Solche Worte sind nicht primär angestrebt.
- Der Eingriff soll möglichts klein sein.
- vgl. Punkt 2. Wobei der Wert bei 6 statistisch relevanter ist.






Der erste visuelle Eindruck gibt nun schon wieder, wie gut das angestrebte “Ideal”(eine grosse Fläche) erreicht wird . Zudem gibt er Aufschluss zu einzelnen Parametern. Z. B.: Wie originär ein Wort ist. So kommen “Sabotiveltern”, der “Plaquegeist” und die “Exklavenhaltung” laut Google nur in enzyglobe vor, was anhand der Ecke unten rechts gut erkennbar ist.



Von einem strengen wissenschaftlichen Standpunkt betrachtet hat es da natürlich allzuviele Fragezeichen. Dafür verantwortlich sind einerseits die “weichen” Parameter, vorallem der eingangs als “Bezug zwischen Ausgangswort und Wortschöpfung” definierte Wert, andererseits aber auch die Aussagekraft von Googles Suchalgorithmus.

Das aussagekräftige Wörtchen “Leerm” zum Beispiel ist in verschiedener Hinsicht ein interessanter Fall. In erster Linie erkennt man daran schön, dass der Parameter “Bezüge” ziemlich willkürlich gesetzt ist. Je nachdem ob man das Diagramm mit einem Bezug Leerm-leer oder Leerm-Lärm erstellt, kommen da ganz andere Werte zu Tage. Zudem, wer es bis jetzt noch nicht gemerkt hat, sind nicht alle Skalen linear unterteilt. Die beiden Google-Skalen sind wegen der grossen Breite der Werte gegen oben rasant ansteigend.
Zudem bietet das Wort Leerm mit den ähnlichen Wörtern “leer”, “lern”, “lehrn” und dem Homophon “Lärm” viel Anlass zur Verwirrung und wohl auch zu falscher Orthographie.
Lange Rede, kurzer Sinn: Sind irgenwdie nett, die Diagramme.
Leave a comment